Abstract
This paper details the rationale, structure, and potential applications of a novel screening tool for predicting substance use disorders (SUDs), highlighting how machine learning can revolutionize SUD risk assessment and inform targeted prevention and intervention strategies. SUDs pose a significant public health challenge, profoundly affecting individuals, their families, communities, and the healthcare system at large. Given these alarming trends, it is imperative to prioritize the early and precise identification of individuals at risk, enabling timely intervention and preventive measures. This study proposes the development of a novel screening tool that merges the well-established CRAFFT 2.1 questionnaire with genetic testing to formulate a comprehensive risk score enhanced by the predictive power of machine learning algorithms such as Random Forest (RF). By identifying complex patterns among genetic and behavioral data using machine learning, this study aims to overcome the limitations of traditional screening methods, which rely heavily on self-reported information and often fail to capture the intricate interplay of genetic predispositions and behavioral patterns in SUD risk. This comprehensive methodology aims to deliver a thorough risk assessment, enhance the precision of identifying at-risk individuals, and facilitate timely, personalized interventions tailored to the unique needs of each individual.
Keywords: substance use disorders (SUDs), random forest (RF), screening tool, risk score, intervention, genetic testing, CRAFFT 2.1 questionnaire, machine learning
© 2025 under the terms of the J ATE Open Access Publishing Agreement
Introduction
SUDs (substance use disorders) impose significant burdens on individuals, families, and communities, highlighting the urgent need for early detection and intervention strategies [1]. Early detection not only helps mitigate the potential for developing severe substance use issues but also supports targeted treatment approaches that can significantly improve long-term outcomes for at-risk populations [2]. The proposed screening tool adeptly integrates the CRAFFT 2.1 questionnaire with genetic testing and employs advanced machine learning algorithms, thereby establishing an innovative framework for the early screening and detection of SUDs.
The CRAFFT 2.1 questionnaire is a validated screening tool specifically designed to assess substance use and related behaviors among adolescents, demonstrating high sensitivity and specificity in identifying those at risk for substance use disorders [3]. The CRAFFT 2.1 “is the most well-studied adolescent substance use screener available and has been shown to be valid for adolescents from diverse socioeconomic and racial/ethnic backgrounds [4].”
Research indicates that genetic predispositions significantly influence the risk of developing SUDs, with heritability estimates suggesting these factors contribute to approximately 40–60% of the overall risk [5]. Genome-wide association studies (GWAS) have identified several single nucleotide polymorphisms (SNPs) associated with SUDs, particularly in the context of alcohol and nicotine dependence [6]. These genetic markers are situated within genes that influence drug metabolism, receptor function, and neurotransmitter pathways, offering valuable insights into genetic contributions to substance use behaviors. Despite the promising insights offered by genetic testing, individual SNPs can have modest effects, necessitating the construction of polygenic risk scores (PRSs) that aggregate the impact of multiple SNPs to yield a more informative measure of genetic predisposition [7].
Machine learning will play a pivotal role in enhancing the predictive capabilities of the proposed screening tool. By analyzing a robust dataset that includes both CRAFFT 2.1 scores and genetic information, machine learning algorithms, particularly RF (random forest), will be employed to develop a comprehensive risk score prediction model [8]. This model will not only identify complex patterns and interactions among various risk factors—such as genetic predispositions, behavioral indicators, and demographic variables—but will also improve the overall accuracy of risk assessments [9]. Machine learning algorithms excel in processing high-dimensional data, enabling them to uncover subtle relationships that may not be immediately apparent through traditional statistical methods [10]. By iteratively learning from the training dataset, the algorithms will refine their predictions, optimizing sensitivity and specificity in identifying adolescents at risk for SUDs [2].
Additionally, the use of cross-validation techniques will ensure that the model is generalizable and robust, thus allowing for reliable application in clinical settings [1]. Ultimately, this integration of machine learning, genetics, and a behavioral questionnaire into the screening tool is anticipated to facilitate personalized risk assessments. Personalized assessments enable healthcare providers to tailor interventions more effectively based on the unique characteristics and circumstances of each individual. By harnessing the power of machine learning, this study aims to advance the field of substance use disorder prevention and intervention, paving the way for innovative and effective strategies to address this critical public health issue.
Literature Review
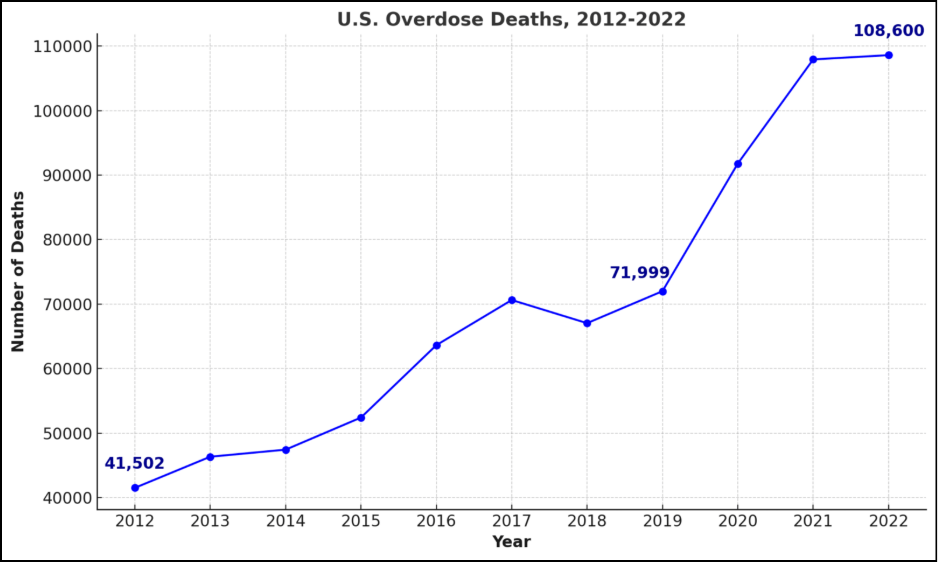
Current research on SUD screening underscores the need for more accurate methods that address the limitations of traditional approaches. Early detection is vital for effective intervention, given the significant personal and societal impacts of SUD, such as increased crime, homelessness, and healthcare strain [1,5]. Early interventions can improve long-term outcomes by helping individuals develop coping mechanisms before substance use escalates into chronic disorders [2]. However, traditional SUD screening methods often fail to account for the complex interplay of genetic and behavioral factors that influence SUD risk [7,8].
Emerging approaches suggest integrating genetic testing with behavioral questionnaires for a more comprehensive risk assessment. The CRAFFT 2.1 questionnaire is “brief and efficient enough to be used as part of universal screening efforts in busy medical and community health settings, and yields information that can serve as the basis for early intervention and counseling to enhance motivation for behavior change [4].” Genetic testing further strengthens this approach by identifying SNPs associated with SUD risk, particularly in genes related to drug metabolism and receptor activity [6].
Machine learning has the potential to transform SUD risk prediction by analyzing complex, high-dimensional data. Algorithms like RF can integrate genetic, behavioral, and demographic data to identify nuanced interactions that influence SUD risk, thereby increasing predictive accuracy [9,10]. This data-driven approach can also support the development of personalized risk scores, enabling targeted prevention strategies that are tailored to individual risk factors [8]. A recent study has demonstrated the efficacy of machine learning methodologies in predicting the trajectory of substance use severity over time, which is crucial for identifying individuals at high risk for developing SUDs [9].
While these innovative methods show promise, the literature emphasizes the need for thorough validation to establish clinical utility. Future research should address potential limitations, such as the cost and accessibility of genetic testing, ethical considerations, and the need for diverse study populations [5]. Expanding research to include additional factors, like family history and environmental influences, can further enhance the tool’s generalizability and predictive power [6].
Methods
Participants
Data for this study will be drawn from longitudinal cohorts, such as the Adolescent Brain Cognitive Development (ABCD) study [2]. This dataset includes comprehensive behavioral, genetic, and environmental measures, tracking youth from childhood to adulthood. Another potential source of data is the National Longitudinal Study of Adolescent to Adult Health (Add Health), a comprehensive longitudinal cohort that tracks the health-related behaviors, social relationships, and genetic data of participants from adolescence into adulthood. The Add Health dataset provides extensive behavioral, demographic, and environmental information, making it a valuable resource for examining risk factors associated with SUDs [12].
The CRAFFT 2.1 Questionnaire
The CRAFFT 2.1 questionnaire is a validated screening tool developed to assess substance use risk and behaviors in adolescents aged 12 to 21. This updated version of the CRAFFT 2.1 includes nine questions (updated from the previous six questions), providing a more comprehensive screening approach for identifying risk related to alcohol and other drug use. As an evidence-based tool widely recommended for adolescent care, CRAFFT 2.1 aligns with the goal of constructing a detailed risk assessment profile for SUDs [4].
Administration
The CRAFFT 2.1 is administered as a self-report questionnaire, ideally completed by the adolescent in a private or clinical setting, such as a waiting room or exam room, to ensure confidentiality and promote honesty. To encourage honest self-reporting, it is key to create a setting where adolescents can respond privately and without their parents viewing their answers. By ensuring privacy and confidentiality, adolescents are more likely to provide accurate information regarding sensitive topics such as substance use. In settings where self-administration is impractical, a clinician-administered interview option is available. This flexibility allows CRAFFT 2.1 to adapt to different clinical environments, maintaining the integrity and confidentiality of responses, which is crucial for accurate assessment [4].
Scoring Method and Application in Study
CRAFFT 2.1 includes an initial set of three opening questions, or “Part A,” that screens for recent use of alcohol, cannabis, and other substances. If the adolescent answers “Yes” to any Part A question, they proceed to “Part B,” which includes six additional questions that explore behaviors and situations associated with substance use risk, captured by the acronym CRAFFT (Car, Relax, Alone, Forget, Family/Friends, Trouble). Each “Yes” response in Part B scores one point, yielding a total score range from 0 to 6 for Part B. A score of 2 or higher in Part B indicates a high risk for SUDs, signaling the need for further evaluation or intervention [4]. In this study, CRAFFT 2.1 scores will be combined with genetic data and analyzed using machine learning algorithms to enhance the precision of SUD risk predictions, providing a nuanced understanding of individual risk factors among adolescents.
Genetic Testing
The proposed genetic testing procedure aims to assess an individual’s genetic predisposition to SUDs by analyzing a panel of SNPs and calculating a weighted PRS. GWAS have identified specific SNPs that are associated with an increased risk of SUDs [5]. Testing for these SNPs provides an objective measure of genetic susceptibility, allowing for a PRS to be calculated and complementing the behavioral data from questionnaires [7].
Sample Collection & SNP Analysis
The process begins with collecting either a saliva or blood sample from each participant. These samples contain DNA, which will be analyzed for specific genetic variations associated with SUDs [6]. The collected DNA samples are analyzed for specific single nucleotide polymorphisms (SNPs), which represent variations in the DNA sequence.
- Functional SNPs. Some SNPs directly affect gene function, impacting protein production or gene regulation. These are called “functional SNPs” and are more likely to have a noticeable effect on an individual’s phenotype, including vulnerability to diseases like SUDs [6].
- Tag SNPs. SNPs can be grouped based on linkage disequilibrium (LD), meaning they are inherited together due to their close proximity on a chromosome. This allows researchers to select “tag SNPs” that represent a larger group of correlated SNPs, making GWAS more efficient [5].
Weighted PRS Calculation
After analyzing the individual’s genotype at each SNP in the panel, a weighted PRS is calculated. The PRS represents an individual’s estimated genetic predisposition to a particular trait or disease, in this case, SUDs. The weighting of each SNP is based on effect size estimates derived from large-scale GWAS [6].
- Aggregate Risk. The PRS aggregates the effects of multiple risk-associated SNPs to provide a comprehensive measure of genetic predisposition. This recognizes the polygenic nature of addiction, where multiple genes contribute to an individual’s overall risk [5,6].
- Effect Size Weighting. SNPs will be weighted based on their effect size, which reflects the magnitude of an SNP’s influence on the trait being studied. SNPs with larger effect sizes will be weighted to contribute more to the PRS, while SNPs with smaller effect sizes will contribute less to the PRS [6].
- Population-Specific Scores. PRS accuracy can vary across populations, particularly for those underrepresented in GWAS. It is crucial to use PRS models developed from ancestrally matched datasets for accurate risk assessment [7].
Machine Learning Technique Using RF Model
Leveraging a large training dataset comprising adolescents with known SUD diagnoses, machine learning algorithms, particularly RF, will be trained to develop a comprehensive risk score prediction model. This model will integrate both the CRAFFT 2.1 score and the weighted PRS, along with other relevant demographic and/or clinical variables, to optimize predictive accuracy. RF has been successfully applied in SUD research to predict the trajectory of substance use severity, identify risk factors, and optimize predictive models [10]. Its ability to assign importance scores to individual features offers valuable insights into the relative contributions of different risk factors.
A large-scale analysis employed a machine learning approach to analyze substance use, initially removing items with more than 70% missing responses, a variance less than 0.1, or those directly querying substance use. The k-nearest-neighbors algorithm (kNN) was then used to impute missing data. The RF method was used to select the most relevant characteristics because it is commonly used to analyze various types of high-volume data. To assess SUD risk, multiple ML algorithms were evaluated, including logistic regression, RF, adaptive boosting (AdaBoost), naive Bayes, support vector machine (SVM), k-nearest neighbors (kNN), and deep neural networks (DNN). The performance of these models was measured using 10-fold cross-validation and the area under the receiver operating characteristic curve (AUROC). While the differences in performance among the models were modest, the Naive Bayes, SVM, and RF models demonstrated slightly better predictive accuracy compared to the other four ML approaches [10].
Among these models, RF was ultimately chosen due to its tree-based structure, which facilitates “if-then” decision-making. Additionally, RF incorporates an embedded feature-selection mechanism that enhances computational efficiency while accounting for interactions between variables. Its versatility also makes it a widely used tool for analyzing complex, high-dimensional datasets. The selected features were determined based on their significance, measured by their ability to distinguish individuals based on outcome probability expressed through information gain. Furthermore, findings from a prospective study indicated that the RF model effectively identified key psychological, health, and environmental factors in early childhood and adolescence, as well as non-normative socialization patterns in later years, that were predictive of SUD risk up to thirty years of age [9,10].
Code Snippet: Training a Random Forest Model
For educational purposes, we provide a sample Python code snippet showcasing how an RF Classifier is implemented using the Scikit-Learn library. This snippet is not directly from our study but serves as a general illustration of the method used. The model is trained on a dataset, makes predictions, and evaluates its performance using accuracy metrics.
# 1. Import Necessary Libraries
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 2. Split the Data into Training and Testing Sets
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
# 3. Initialize the Random Forest Classifier
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# 4. Train the Model
rf_model.fit(X_train, y_train)
# 5. Make Predictions
y_pred = rf_model.predict(X_test)
# 6. Evaluate Model Performance
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 7. Print Sample Predictions
print("Sample predictions:", y_pred[:10]) Step-by-Step Explanation of the Random Forest Model
- Importing Libraries: Scikit-Learn functions are imported to build and evaluate the model.
- Splitting Data: The dataset is divided into 80% training and 20% testing to evaluate performance.
- Initializing the Model: A Random Forest Classifier is created with 100 decision trees.
- Training the Model: The “.fit()” function trains the model on the training data.
- Making Predictions: The trained model predicts the labels for the test data.
- Evaluating Performance: The accuracy is calculated using “accuracy_score()” comparing actual and predicted values.
- Displaying Output: The first 10 predicted values are presented as the output.
Results
Preliminary Findings and Predicted Outcomes
The proposed RF algorithm is anticipated to demonstrate high accuracy in predicting SUD outcomes, building on previous studies that have successfully applied machine learning techniques to substance use risk prediction. The proposed machine learning model is expected to be a reliable indicator of both current and future SUD, as demonstrated by its performance in detecting and predicting SUD at various assessment points [9]. Based on preliminary analyses, we project that the RF model will achieve a high level of discriminative accuracy, with an AUROC anticipated to exceed 0.80, reflecting strong predictive capability. In addition to overall accuracy, we expect the RF model to identify critical predictors of SUD risk among the factors included in the CRAFFT 2.1 questionnaire. For example, early initiation of substance use may emerge as the most significant predictor, aligning with findings from the ABCD study that link early substance use patterns with later SUD development [2]. The RF algorithm’s feature importance scores will provide a systematic approach to ranking these predictors, enabling healthcare providers to prioritize targeted interventions effectively.
Comparison Against Traditional Logistic Regression Models
We aim to compare the predictive performance of the RF model against traditional logistic regression models. Initial comparisons suggest that the RF model could improve sensitivity and specificity rates by at least 10%, particularly in identifying high-risk individuals who may not meet traditional diagnostic criteria but exhibit concerning behavioral patterns [10]. Overall, the expected results will not only validate the effectiveness of our novel screening tool but also contribute to understanding SUD trajectories in youth, reinforcing the importance of early identification and intervention efforts.
The Role of Machine Learning in the Analysis of Substance Use and its Outcomes
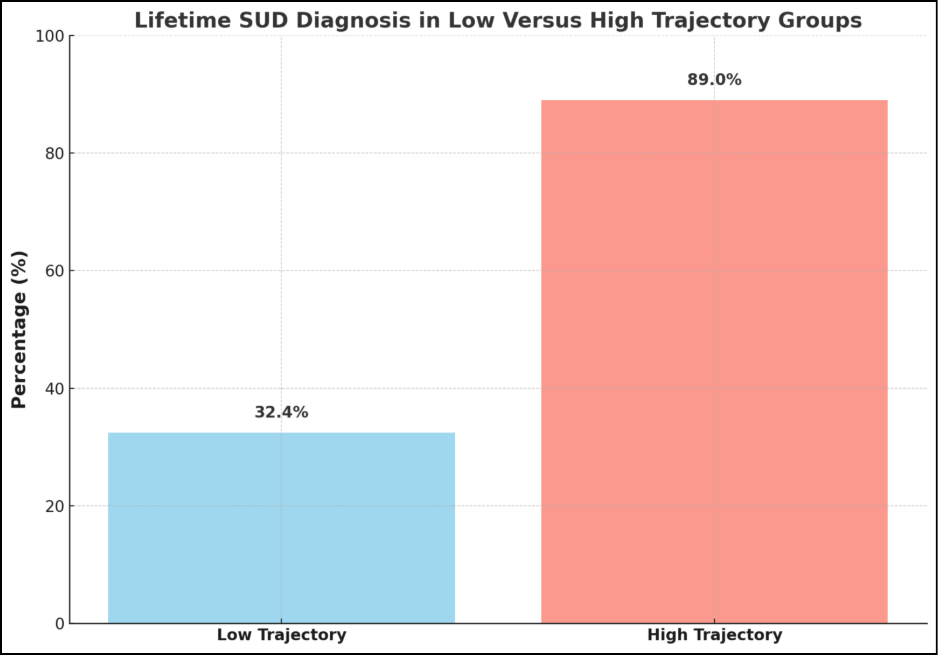
A large study conducted by a team of researchers utilized the SUS (Substance Use Severity) score, a measure based on the harmfulness of 14 substances, to assess substance use severity using machine learning. The study successfully delineated high-severity and low-severity substance use trajectories, highlighting a stark difference in SUD outcomes. The high-severity trajectory group exhibited a significantly higher probability of developing SUD compared to the low-severity trajectory (89.0% vs 32.4%) [9]. This suggests a strong association between the identified trajectory and future SUD development. These results underscore the importance of early identification of individuals in high-severity trajectories, which can be facilitated through machine learning models.
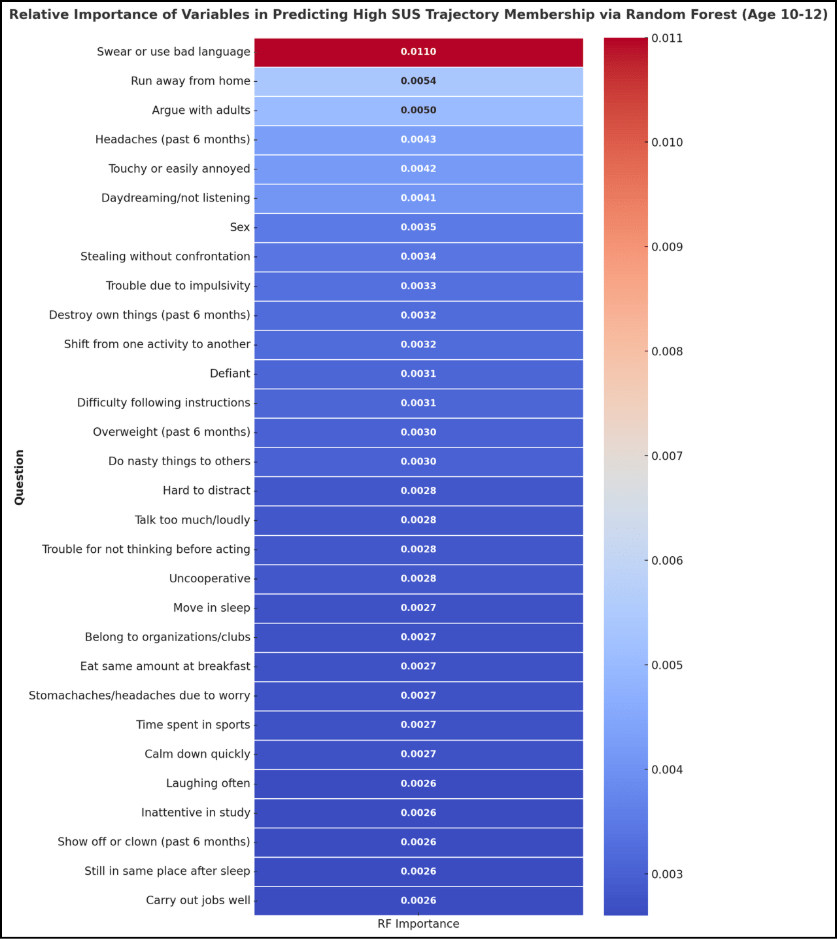
This longitudinal study analyzed data from children, tracking their psychological and health characteristics from ages 10 to 30, and employed various machine learning algorithms to derive meaningful insights. The study employed an extensive set of psychological and health characteristics, using approximately 1,000 features to predict membership in the high-severity trajectory. By utilizing RF, the researchers were able to identify 30 critical psychological traits that optimally predicted trajectory membership. These traits included behavioral indicators such as aggression, defiance, and poor academic performance. The integration of such characteristics into machine learning models allows for a nuanced understanding of the factors contributing to SUD risk and highlights the predictive power of machine learning models in assessing the risk of SUDs [10].
High Accuracy in Detecting Current and Future SUD
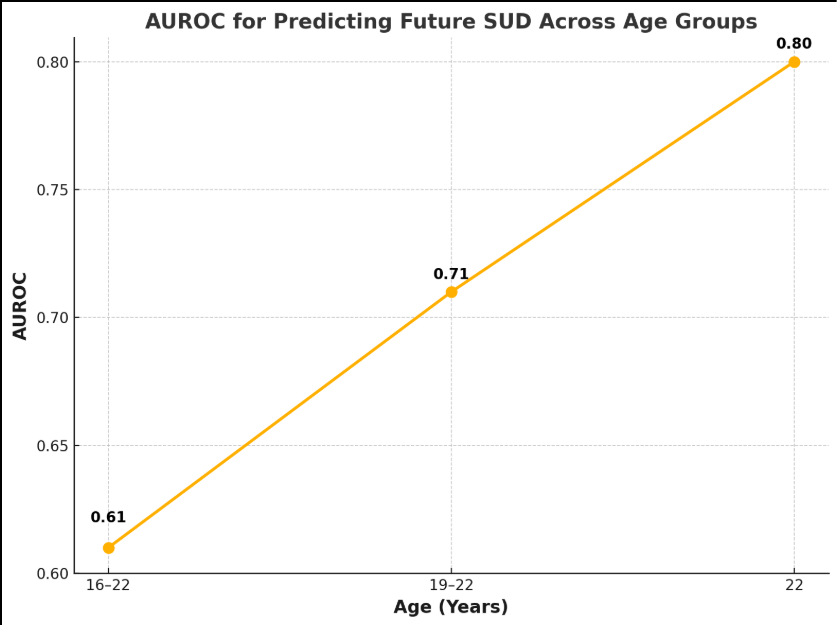
The results of a large study showed that the SUS score exhibited an AUROC greater than 0.80 at all three visits (ages 12-14, 16, and 19) using machine learning algorithms such as RF, indicating their effectiveness in identifying individuals currently experiencing SUDs. As shown in Figure 3, the study found that by leveraging the power of machine learning, the SUS score can predict future SUDs as well, a measure that improves with age. The machine learning model predicted future SUDs with an AUROC of 0.61 in the 16-22 age group, 0.71 in the 19-22 age group, and 0.80 in the 22 age group, highlighting the value of this machine learning model in identifying individuals at risk of developing SUD later in life. The RF model achieved 71% accuracy in predicting trajectory group membership at age 10-12, which increased to 93% by age 22. These high accuracy rates underscore the potential of machine learning in identifying individuals on a trajectory toward SUD, potentially facilitating early intervention and prevention efforts [9].
Trajectory Analysis
Using the SUS scores across multiple assessments, two distinct substance use severity trajectories were identified, which differed significantly in their association with SUD development [9]:
- High-Severity Trajectory. This trajectory was characterized by a sharp increase in substance use severity during adolescence and early adulthood, peaking around age 25 and declining slightly by age 30. Notably, 89.0% of participants in this trajectory developed SUD, indicating a strong link between this pattern of substance use and the development of SUD [9].
- Low-Severity Trajectory. This trajectory exhibited relatively stable and low substance use severity throughout the study period. Notably, only 32.4% of participants in this trajectory developed SUD, demonstrating a clear and significant link between this low-severity pattern of substance use and a reduced risk of developing SUD [9].
Interpretation of Results
Interpreting low-risk results from the screening tool will require careful communication to ensure individuals do not misinterpret the outcome as a guarantee of immunity from developing SUDs. A low-risk trajectory result should be framed as indicating a relatively lower likelihood of developing SUDs based on current factors rather than a definitive prediction of an individual’s future [9,10]. Messaging accompanying the results should explicitly state that SUD risk is dynamic and can change over time due to environmental, behavioral, or genetic factors [5,6]. Even those in the low-risk category still carry the potential for developing SUDs and must remain mindful of their choices regarding substance use. If the individual is a minor, results must be communicated with the parents in an easily understandable manner. Normalizing follow-up screenings and encouraging regular check-ins can help individuals recognize that SUD risk can change over time and that even those in the low-risk category should make informed, responsible decisions and avoid behaviors that could increase their risk in the future [1,2].
Interpreting results indicative of a high-risk trajectory requires precise and clear communication, as it is imperative that individuals fully comprehend the implications of their elevated risk profile. Such results reflect a combination of underlying genetic predispositions and behavioral patterns that place an individual at a significantly higher risk of developing SUDs [5,9]. This trajectory should be treated as a priority for proactive engagement, with recommendations for early intervention programs tailored to mitigate these risks effectively [1,2]. If the individual is a minor, parents must be informed about the significance of the high-risk trajectory and its potential implications for their child’s health. Parents should be informed in a clear and supportive manner while equipping them with the knowledge needed to assist in decision-making and facilitate access to appropriate interventions [2]. Healthcare providers can utilize these results to design targeted strategies, such as intensive therapy, structured behavioral interventions, or family-based approaches, to address the contributing factors comprehensively [10]. Emphasis should also be placed on educating individuals and their support systems about the importance of sustained commitment to intervention plans, as this is essential to reducing the likelihood of SUD development and promoting long-term resilience [9].
Predictive Power of Psychological and Health Characteristics
A large-scale analysis employed machine learning algorithms, specifically RF, to identify a set of 30 psychological and health characteristics that could predict membership in the high-severity substance use trajectory. The machine learning analysis revealed that these 30 characteristics, assessed during childhood (ages 10-12), were significantly associated with membership in the high-severity trajectory, demonstrating the feasibility of machine learning analysis in identifying at-risk individuals early in life. The identified characteristics largely reflected poor psychological self-regulation and socially non-normative behaviors, including aggression, defiance, poor academic performance, rule-breaking behaviors, and indicators of poor physical and mental health. These findings emphasize the multifaceted nature of SUD risk and the importance of assessing a broad range of factors in screening efforts [9].
Machine Learning: The Bridge Between CRAFFT and Genetic Data
Genetic testing offers an objective measure of SUD risk, complementing the subjective nature of self-reported questionnaires. Research has consistently shown that drug-related phenotypes are complex traits significantly influenced by genetic factors [7]. GWAS, a powerful tool for identifying genetic associations, have uncovered numerous SNPs linked to various SUDs, particularly those involving alcohol and nicotine dependence. Testing for these SNPs is pivotal for this study, as they often reside within genes essential to drug metabolism and receptor activity, providing valuable insights into individual susceptibility to SUDs [6].
The CRAFFT 2.1 questionnaire is a screening tool used to assess substance use among adolescents. Data obtained from the CRAFFT 2.1 questionnaire significantly contributes to SUD risk assessment by providing essential behavioral data that improves the accuracy and personalization of SUD risk predictions. When integrated with genetic data, utilizing the CRAFFT 2.1 questionnaire facilitates the generation of individualized risk scores, representing a substantial step toward personalized interventions and precision-based care in SUD prevention [4].
The application of machine learning in SUD prediction marks a significant advancement in addiction research. The ability to analyze large datasets and extract relevant predictors of SUD risk paves the way for innovative screening tools that can improve outcomes in at-risk populations. Machine learning excels at uncovering intricate relationships between variables that might not be readily apparent through traditional statistical methods [9]. By analyzing the interplay between genetic predispositions (PRS), self-reported behaviors (CRAFFT), and other potential risk factors, machine learning models can identify complex interactions that contribute to SUD vulnerability [10]. This holistic approach leverages the analytical power of machine learning to combine genetic data with behavioral data to form a more comprehensive risk score when compared to relying on individual variables in isolation.
Discussion
Integrative Approach Using Genetic Data and Machine Learning
The proposed screening tool represents a potentially groundbreaking advancement in SUD risk assessment by integrating the CRAFFT 2.1 questionnaire, genetic testing, and machine learning to form a comprehensive risk score. This integrative approach addresses the limitations of traditional screening methods, offering several advantages. Machine learning algorithms offer a sophisticated means of analyzing complex datasets and extracting meaningful patterns, making them particularly well-suited for integrating CRAFFT scores and genetic information. Among the array of machine learning techniques, RF stands out as a robust and versatile algorithm capable of handling high-dimensional data and identifying complex interactions among variables, making it a great fit for the analysis of genetic and behavioral data for our study [8].
Early Identification of SUD Risk
The findings from a large-scale analysis emphasize the potential of machine learning to inform preventive measures against SUDs. By identifying high-risk individuals early on, targeted interventions can be implemented to mitigate the risk of developing SUD. This proactive approach could lead to more effective treatment plans tailored to the unique psychological and behavioral profiles of at-risk adolescents. Early detection of high-risk individuals is essential for enabling timely interventions that can redirect their development away from maladaptive patterns and toward healthier behaviors. This not only reduces their risk of developing SUD but also increases their potential to contribute productively to society [1,9]. By identifying individuals with high-risk trajectories earlier, resources can be allocated where they are needed most to ensure that these individuals receive the support they need to lead lives that add value to society. Identifying individuals with low-risk trajectory early on helps to ensure that the proper resources are concentrated on those in the high-risk trajectory, while those in the low-risk trajectory might receive lighter-touch interventions. This not only maximizes the impact of preventive efforts of the tool but also helps to prevent over-intervention for those in the low-risk trajectory and a lack of intervention for those in the high-risk trajectory [8,10].
Continuous Optimization
Machine learning algorithms possess the ability to learn from vast datasets, iteratively refining the prediction model to achieve superior performance. This continuous optimization process leads to improved sensitivity, specificity, and AUROC, enhancing the accuracy of identifying individuals at risk for SUD [8]. Machine learning enables the development of individualized risk scores tailored to each person’s unique characteristics and circumstances. This personalized approach acknowledges that SUD risk is not uniform but varies based on a complex interplay of factors. By tailoring risk assessment to individual profiles, this tool can potentially enhance the effectiveness of preventive interventions and treatment strategies. If, for example, an adolescent initially has a low risk but later encounters adverse experiences or exhibits risky behaviors, the model adjusts their risk score accordingly. This adaptability ensures that interventions remain relevant and timely, potentially reducing the likelihood of substance use escalation [1,9].
Enhanced Accuracy
Combining self-reported data with objective genetic information, facilitated by machine learning’s ability to discern complex interactions, promises a more accurate and reliable risk score compared to single-source assessments [1]. The implementation of machine learning, particularly the RF algorithm, achieved impressive accuracy levels in predicting high versus low trajectory membership. At the initial assessment age of 10–12 years, the model achieved a prediction accuracy of 71%, which significantly increased to 93% by the age of 22 years [9]. Such improvements in predictive accuracy highlight the potential of ML in monitoring substance use behaviors over critical developmental periods.
Personalized Prevention and Customized Intervention Strategies
This study is grounded in the machine learning model’s capacity to analyze extensive, multifaceted data, including genetic markers, behavioral assessments like the CRAFFT 2.1 questionnaire, and demographic factors. By synthesizing this information, the model will generate a nuanced risk score that reflects each individual’s unique combination of factors contributing to their susceptibility to SUDs. Using machine learning to generate personalized risk scores represents a significant advancement toward individualized care in SUD prevention. By addressing the unique aspects of each person’s risk profile, this approach guides interventions that are more likely to resonate with and benefit individuals, ultimately enhancing the efficacy of prevention strategies [3,6].
Unlike traditional screening tools that may apply a “one-size-fits-all” approach, a personalized risk score allows healthcare providers to tailor prevention plans to an individual’s specific profile. For instance, if genetic predispositions strongly influence a person’s risk, interventions can focus on mitigating environmental triggers or providing education on stress management techniques. Conversely, if behavioral factors are prominent, targeted strategies like social skills training or behavioral therapy may be prioritized [5,10]. Personalized risk scores help clinicians pinpoint the exact level and type of support an individual may need. For example, someone at moderate risk might benefit from regular check-ins and educational sessions, while those with high risk due to genetic and behavioral factors might require intensive interventions, such as counseling or regular assessments [8,9]. This precision is especially valuable given that early, targeted intervention has been shown to significantly improve long-term outcomes in at-risk populations [2].
Limitations
Accessibility and Cost of Genetic Testing
One key limitation of this tool is the cost and accessibility of genetic testing. While genetic data provide critical insights into individual susceptibility to SUDs, the expense and limited availability of testing, especially in underserved areas, could hinder widespread application [7]. Addressing this will require further research into cost-effective strategies and partnerships to improve accessibility. We plan to explore partnerships with healthcare providers, insurers, and community organizations to subsidize testing for at-risk populations, thereby enhancing the feasibility of genetic testing.
Ethical and Privacy Concerns
The use of genetic information in screening raises important ethical issues. Genetic data, if not handled securely, can lead to privacy concerns, including unauthorized sharing or misuse. Additionally, there are risks related to potential stigma or discrimination if genetic predispositions are known by insurers, employers, or schools. Strict data protection measures, consent protocols, and ethical guidelines are essential to ensure that genetic information is used responsibly [5]. The Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule was enacted in 1996 and safeguards the privacy of patients’ identifiable health data, known as Protected Health Information (PHI), managed by covered entities such as healthcare providers and insurers. While strict rules control the sharing of PHI, these do not extend to health information that has been de-identified, allowing it to be used or disclosed without restriction. The Genetic Information Nondiscrimination Act (GINA), passed by Congress in 2008, was designed to safeguard individuals’ genetic information by restricting access to health insurers and employers. The GINA Act prohibits these organizations from using personal genetic data for discriminatory purposes. There is still apprehension about how genomic data might be utilized to unfairly disadvantage individuals seeking life insurance, long-term care policies, or disability coverage [13].
Potential for False Positives and Negatives
No screening tool is perfect, and the integration of genetic, behavioral, and machine-learning components could lead to both false positives and negatives. False positives may cause undue anxiety or lead to unnecessary interventions, while false negatives might delay help for those at genuine risk. Ensuring high sensitivity and specificity in the tool, along with clear follow-up protocols, will be essential to address these potential outcomes [10]. Longitudinal studies using machine learning algorithms have identified psychological and health characteristics that predict membership in high-risk substance use trajectories, indicating that these predictive models, while valuable, are not infallible and require continuous validation and refinement [9].
Adaptability of Machine Learning Model Across Diverse Datasets
Machine learning models require large, diverse datasets to be accurate and effective across different populations. If the dataset used to train the model lacks diversity, there’s a risk that the screening tool may not perform as well across various demographic groups, such as those defined by race, ethnicity, socioeconomic status, or geographic location. PRS, weighted by effect sizes from GWAS, may not always transfer into other ancestral populations, as GWAS have been overwhelmingly limited to individuals of European ancestries. Continuous validation and adjustments to the model will be essential to ensure it remains generalizable and equitable. In a follow-up paper, we plan to integrate techniques such as transfer learning or fine-tuning the model with data from diverse ancestral populations to improve polygenic risk prediction across different ancestries [1].
Reliance on Self-Reported Data in CRAFFT 2.1 Questionnaire
We acknowledge the potential for biases in self-reported data, a common challenge in behavioral research. The CRAFFT 2.1 questionnaire, however, is a validated tool with established sensitivity and specificity for identifying substance use risk in adolescents. Despite the questionnaire’s validated effectiveness, the reliance on self-reported data may introduce biases, such as underreporting or social-desirability bias, which could skew results [4]. To mitigate this, we integrate objective genetic data, analyzed through GWAS to calculate PRS, providing an independent risk measure [1,7]. The RF algorithm is designed to weigh both behavioral and genetic data, potentially reducing the impact of self-report biases by identifying patterns across both domains [9,10]. In a follow-up paper, we will conduct sensitivity analyses to evaluate the extent to which potential underreporting may influence model performance.
Requirements for Clinical Implementation
Integrating genetic testing, behavioral assessments, and machine learning in clinical settings requires trained personnel and proper infrastructure, which may not be readily available in all healthcare environments. To address this limitation and optimize the implementation of this screening tool, it is essential to adopt a patient-centered approach that actively engages individuals in their healthcare decisions while ensuring that all clinic staff are properly briefed on how to implement this tool into their practice. We plan to establish partnerships with specialized centers and leverage telehealth solutions to broaden access to this tool in underserved communities. This approach ensures equitable access to our advanced screening tool for all patients, irrespective of geographic location or socioeconomic status [1]. Through the employment of these strategies, we intend to mitigate this limitation and further examine its implications in a follow-up paper.
Future Directions for Research
Clinical Utility Evaluation
To comprehensively evaluate clinical utility, it is essential to conduct rigorous clinical trials to assess the tool’s effectiveness in real-world settings, focusing on its impact on SUD prevention and treatment outcomes [10]. Evaluation should assess whether these screening tools can effectively connect at-risk individuals with appropriate interventions [4]. This includes evaluating the practicality of integrating the tool into routine clinical workflows, as well as assessing its economic impact by considering both direct and indirect costs. Longitudinal studies should focus on predictive ability [1]. These studies could show that psychological dysregulation in childhood and non-normative socialization in adolescence are useful characteristics for predicting risk [10]. Furthermore, these studies should track patient outcomes to evaluate the effectiveness of interventions initiated based on the tool’s assessment.
Future Enhancements
Future iterations of the tool could be enhanced by incorporating additional risk factors, such as family history of SUD, mental health disorders, history of trauma or adverse childhood experiences, and environmental influences [1]. This expansion would further enhance the comprehensiveness and predictive power of the risk score. The accuracy of PRSs may vary across different racial and ethnic groups due to differences in genetic background and allele frequencies. Future research is needed to assess the generalizability of the tool and develop population-specific risk score adjustments to ensure equitable application across diverse populations [6].
Validation and Refinement
To establish the reliability and clinical utility of the proposed screening tool, a rigorous validation process is essential. This process will involve training and testing datasets, assessing the screening tool’s performance and overall accuracy, and ultimately establishing a risk score cutoff to optimize the utility of the screening tool.
- Training and Testing Datasets. To prevent overfitting and ensure model reliability, the collected data will be divided into separate training and testing datasets. The training dataset will be used to train the machine learning algorithm and develop the risk score prediction model. The testing dataset, comprising individuals not included in the training process, will be used to evaluate the model’s performance on unseen data.
- Performance Evaluation. The screening tool’s performance will be assessed using standard psychometric measures, including sensitivity, specificity, and AUC. Sensitivity measures the proportion of individuals with SUD correctly identified by the tool, while specificity measures individuals without SUD correctly identified as not at risk [9]. The AUC reflects the overall accuracy of the tool, with higher values indicating better discrimination between individuals in the high-risk trajectory and low-risk trajectory. We plan to assess the performance of the screening tool over the next year using these measures and publish our findings in a follow-up paper.
Risk Score Cutoff Determination. Based on the tool’s performance characteristics, a risk score cutoff will be established to differentiate high-risk individuals from those at lower risk. Establishing an appropriate risk score cutoff is essential for optimizing clinical decision-making. This cutoff determination process will involve balancing sensitivity and specificity to optimize the tool’s clinical utility, considering the potential benefits and harms of false positive and false negative results. The impact of risk score cutoff values on predictive accuracy and real-world application should be analyzed to refine the model’s clinical utility [1,9].
Conclusion
The integration of the CRAFFT 2.1 questionnaire, genetic testing, and machine learning into a comprehensive screening tool represents a transformative approach to the early detection and assessment of SUDs [3,6]. This study outlines the development and validation of a novel screening tool designed to improve the identification of adolescents at risk for SUD, ultimately facilitating timely and personalized prevention and intervention strategies. Machine learning has emerged as a pivotal force in enhancing the predictive accuracy of SUD risk assessments. Studies have demonstrated that machine learning algorithms, particularly the RF model, can effectively analyze complex datasets to uncover intricate relationships between genetic predispositions, self-reported behaviors, and other risk factors [9,10]. By employing these advanced analytical techniques, the proposed screening tool moves beyond the limitations of solely self-reported data, incorporating objective genetic information alongside questionnaire responses to provide a more comprehensive insight into individual susceptibility to SUDs [7]. The amalgamation of the CRAFFT 2.1 questionnaire with genetic testing allows for the development of a comprehensive risk profile that accounts for both behavioral and biological determinants of SUD risk. This integrative approach not only enhances the accuracy of risk assessments but also fosters a deeper understanding of the multifactorial nature of addiction [5]. As genetic testing becomes more accessible and cost-effective, the ability to generate polygenic risk scores (PRS) will further enrich the screening process, providing clinicians with invaluable insights that can guide personalized treatment options [6]. Moreover, the proposed tool addresses a critical gap in current SUD screening methodologies. By focusing on early detection, it has the potential to identify at-risk adolescents before the onset of more severe substance use issues. Early identification is crucial for implementing targeted interventions that can significantly alter the trajectory of substance use and mitigate the associated health and social consequences [8]. The development of this novel SUD screening tool marks a significant advancement in the field of addiction research and prevention. By integrating the CRAFFT 2.1 questionnaire, genetic testing, and machine learning, this innovative approach offers a comprehensive framework for identifying adolescents at risk for SUDs. Ultimately, it holds the potential to revolutionize how we assess and address substance use issues, paving the way for more effective and personalized intervention strategies that can significantly improve public health outcomes.
Acknowledgments
The authors gratefully acknowledge Wake Technical Community College, particularly the Biotechnologies Division, for providing the facilities and academic support essential to this research. Special recognition is given to Chris Budnick, MSW, LCSW, LCAS, CCS, Founder and Executive Director of Healing Transitions and Adjunct Instructor with the North Carolina State University Department of Social Work, for his expert consultation and valuable contributions to advancing the understanding and treatment of substance use disorders. This research received no specific grant from any funding agency in the public, commercial, or not‑for‑profit sectors.
Disclosures
The authors declare that they have no conflicts of interest to disclose related to this research, its authorship, or its publication.
[1] P. B. Barr, M. N. Driver, S. I.-C. Kuo, M. Stephenson, F. Aliev, R. Karlsson Linnér, J. Marks, A. P. Anokhin, K. Bucholz, G. Chan, and H. J. Edenberg, “Clinical, environmental, and genetic risk factors for substance use disorders: Characterizing combined effects across multiple cohorts,” Mol. Psychiatry, vol. 27, no. 11, pp. 4071–4082, 2022. doi: 10.1038/s41380-022-01450-y.
[2] K. M. Lisdahl, K. J. Sher, S. F. Tapert, et al., “Substance use patterns in 9–10 year olds: Baseline findings from the Adolescent Brain Cognitive Development (ABCD) study,” Drug Alcohol Depend., vol. 227, 2021. doi: 10.1016/j.drugalcdep.2021.108946.
[3] V. Caretti, A. Gori, G. Craparo, M. Giannini, G. Iraci-Sareri, and A. Schimmenti, “A new measure for assessing substance-related and addictive disorders: The Addictive Behavior Questionnaire (ABQ),” Addict. Behav., vol. 76, pp. 120–126, 2018. doi: 10.1016/j.addbeh.2017.07.002.
[4] Center for Adolescent Substance Use Research, CRAFFT 2.1 Provider Manual. Boston: Boston Children’s Hospital, 2018.
[5] F. Ducci and D. Goldman, “The genetic basis of addictive disorders,” Psychol. Med., vol. 42, no. 6, pp. 993–1003, 2012. doi: 10.1017/S0033291711002040.
[6] A. S. Hatoum, S. M. C. Colbert, E. C. Johnson, S. B. Huggett, J. D. Deak, G. Pathak, M. V. Jennings, S. E. Paul, N. R. Karcher, I. Hansen, and D. A. A. Baranger, “Multivariate genome-wide association meta-analysis of over 1 million subjects identifies loci underlying multiple substance use disorders,” Nat. Genet., vol. 55, no. 3, pp. 331–340, 2023. doi: 10.1038/s41588-022-01135-0.
[7] K. M. Bühler, E. Giné, V. Echeverry-Alzate, J. Calleja-Conde, F. Rodriguez de Fonseca, and J. A. López-Moreno, “Common single nucleotide variants underlying drug addiction: More than a decade of research,” Addict. Biol., vol. 20, no. 4, pp. 674–706, 2015. doi: 10.1111/adb.12116.
[8] Y. Ahna and J. Vassileva, “Machine learning identifies substance-specific behavioral markers for opiate and stimulant dependence,” Drug Alcohol Depend., vol. 160, pp. 42–50, 2016. doi: 10.1016/j.drugalcdep.2016.02.009.
[9] Z. Hu, Y. Jing, Y. Xue, P. Fan, L. Wang, M. Vanyukov, L. Kirisci, J. Wang, and R. E. Tarter, “Analysis of substance use and its outcomes by machine learning: II. Derivation and prediction of the trajectory of substance use severity,” Drug Alcohol Depend., vol. 206, p. 107604, 2020. doi: 10.1016/j.drugalcdep.2019.107604.
[10] Y. Jing, Z. Hu, P. Fan, Y. Xue, L. Wang, R. E. Tarter, L. Kirisci, J. Wang, M. Vanyukov, and X.-Q. Xie, “Analysis of substance use and its outcomes by machine learning I. Childhood evaluation of liability to substance use disorder,” J. Stud. Alcohol Drugs, vol. 81, no. 2, pp. 142–152, 2020. doi: 10.15288/jsad.2020.81.142.
[11] National Institute on Drug Abuse, “Overdose death rates,” U.S. Department of Health and Human Services, 2024. [Online]. Available: https://nida.nih.gov/research-topics/trends-statistics/overdose-death-rates.
[12] Carolina Population Center, “Add Health: Data – Public use data,” University of North Carolina at Chapel Hill. [Online]. Available: https://addhealth.cpc.unc.edu/data/#public-use.
[13] National Human Genome Research Institute, “Privacy issues,” U.S. Department of Health and Human Services. [Online]. Available: https://www.genome.gov/about-genomics/policy-issues/Privacy.